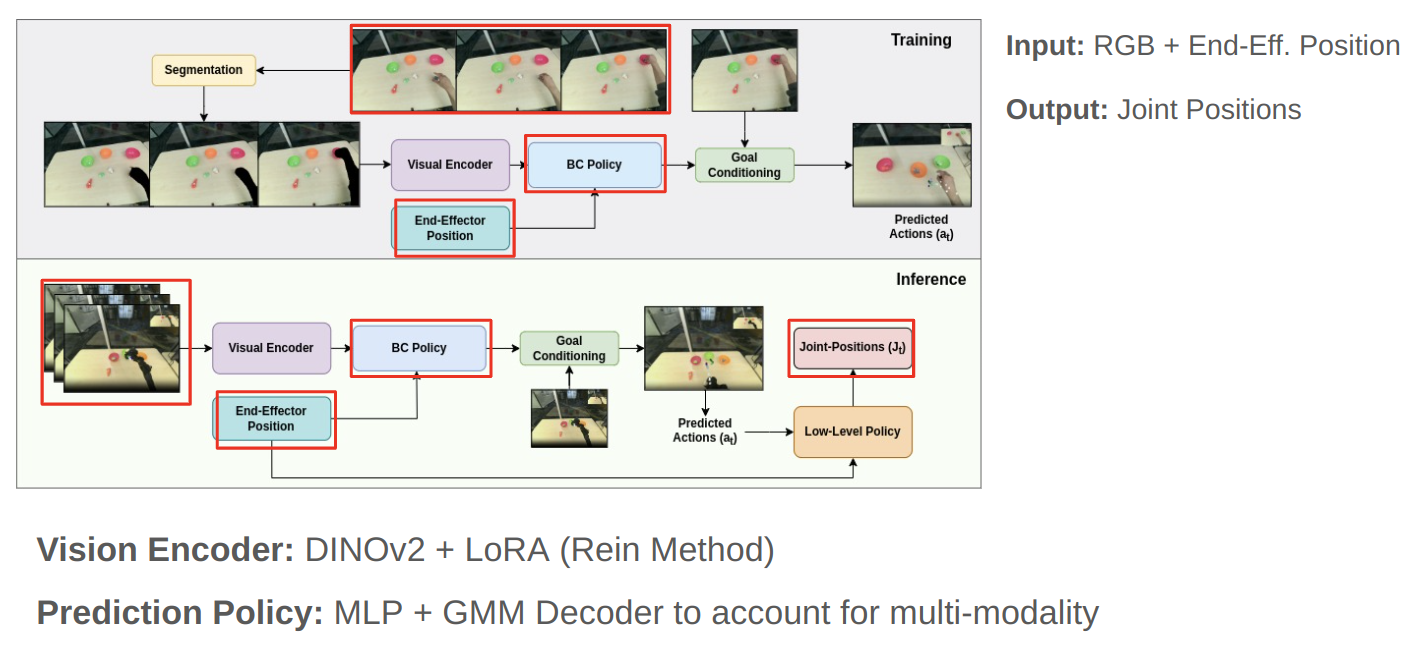
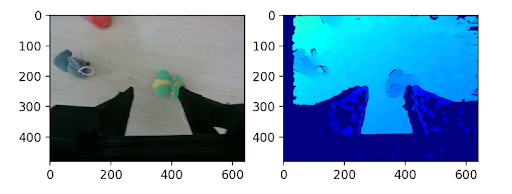
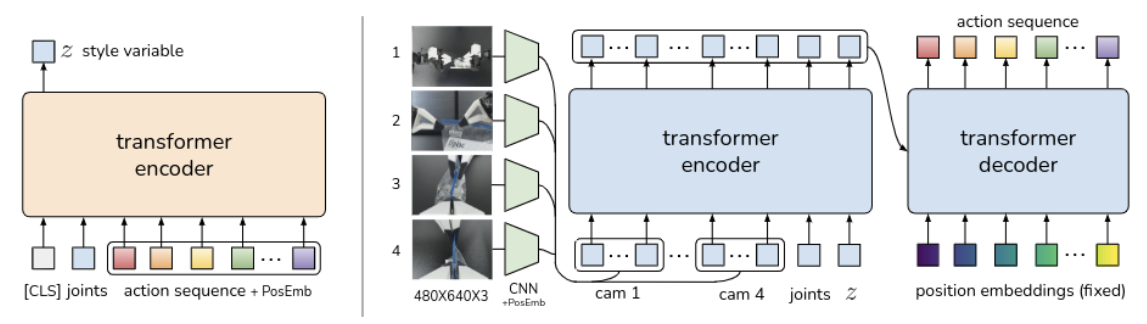
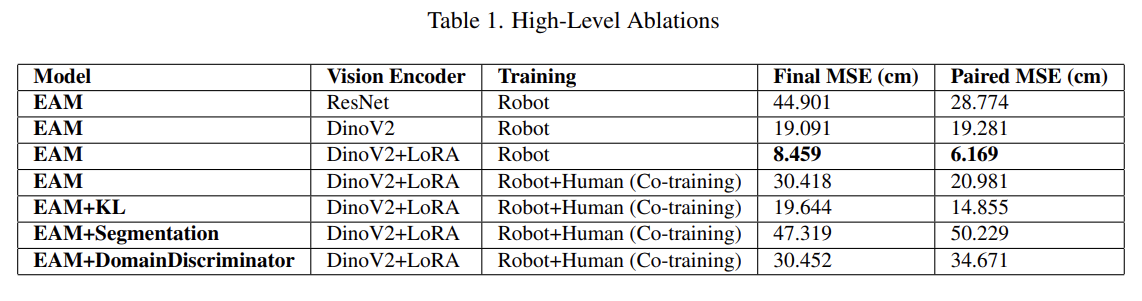
Abstract
Can we learn a hierarchical visuomotor control policy
that can generalize to novel scenes, objects and geometries
without scaling teleoperated robot demonstrations ? Recent
works have shown impressive performance on manipulation
tasks through learning policies leveraging robot teleopera-
tion data collected at scale. To ensure true autonomy in
the real-world these policies should be able to generalize to
multiple tasks, visual domains, and diverse object geome-
tries in unstructured environments. A scalable solution must
reduce the dependence on collecting a large number of tele-
operated demonstrations while simultaneously ensuring the
alternative can be used to learn a representation that guides
low-level control effectively. We propose learning a policy
using human-play data - trajectories of humans freely inter-
acting with their environment. Human-play data provides
rich guidance about high-level actions to the low-level con-
troller. We demonstrate the effectiveness of our high-level
policy by testing with low-level control methods that use few
teleoperation demos. Further, we examine the feasibility
of a hierarchical policy that requires no teleoperation data
and can generalize to any robot embodiment while obeying
the kinematic constraints of the embodiment. We present
our results and ablation studies on tasks evaluated in the
real-world.